2024年4月19日,主题为「“融合创‘新’,数‘智’赋能”—2024艺赛旗春季产品发布会」,在线上顺利举行!
2023 年,ChatGPT 火出了圈,继 ChatGPT 之后,全球各行各业大模型千帆竞发。
在大模型的加持下,超自动化将会产生怎样的“超能力”?
南京大学人工智能学院副院长、艺赛旗首席科学家黎铭教授在艺赛旗2024春季发布会上为我们了带来主题为《基于大模型的流程自动化》的分享。
流程自动化的关键是要理清流程,在完成自动化之前,流程挖掘是非常重要的一步。
企业不管是要做数字化转型,还是要提升经营效率,首先都需要对整个公司的业务进行实时客观的观察和了解。
由于大部分企业的内部涉及多个异构的业务系统,数据往往分散在多个系统中,难以给出一个统一的高质量日志文件。
此外即便通过流程挖掘发现了业务流程中的瓶颈,优化建议的执行和效果验证仍然依赖于人员进行,这需要和用户频繁沟通了解诉求,不同视角的人总结出来的流程可能存在差异,反馈的时间可能较长,带来大量沟通成本,最终导致项目难以推进。
黎教授指出,机器学习是利用经验来提高系统性能的一种技术,它可以从业务数据中自动发现、配置并运行流程,并根据业务条件与变化对自身进行适时调整。机器学习研究的主要产物是算法,这些算法可以在各个行业有广泛应用,包括计算机视觉、人工智能和数据挖掘。
现如今机器学习已经成为人工智能领域的核心研究之一,在各个领域中展现出巨大的潜力和创新能力。计算机领域的最高奖——图灵奖就连续授予了这方面的学者。
除了学术界,政府和工业界也对机器学习给予了高度重视,我国在《新一代人工智能发展规划》里,将机器学习列为需重点研究的关键基础理论之一,美国白宫印发的人工智能白皮书,也将其列为人工智能领域最重要技术之一。
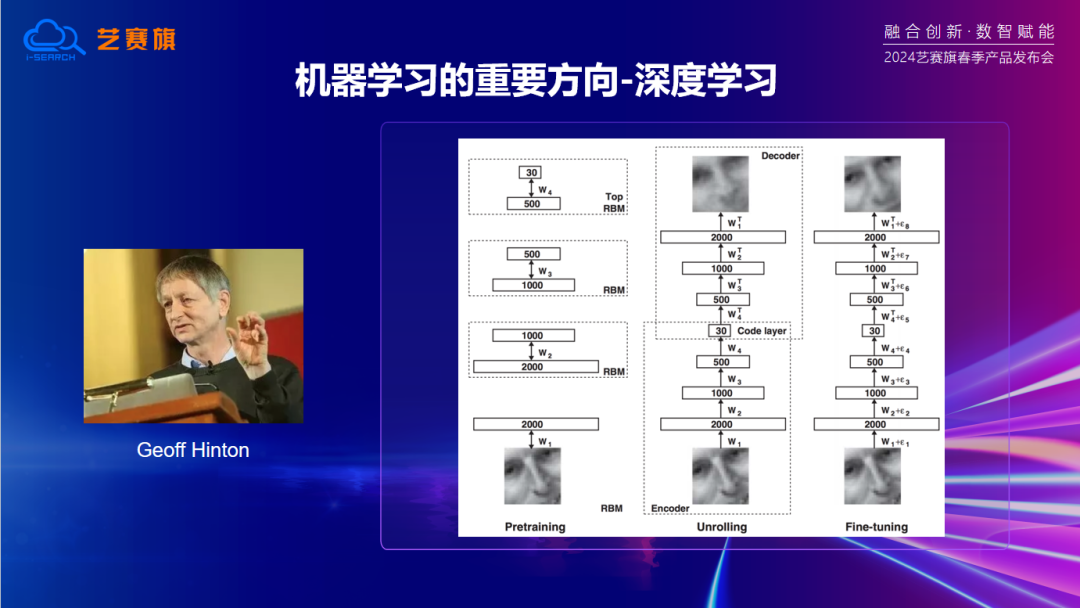
机器学习是随着人工智能发展而兴起的,到了 90 年代开始逐渐受到重视。机器学习的一个重要分支方向是深度学习,由学者 Jeffrey Hinton 在 2006 年提出。深度学习的发展使得机器学习模型能够解决更复杂的问题,例如2016年基于深度学习模型的AlphaGo 就打败了人类顶尖棋手,引起了全世界的轰动。
到了2022年底,基于深度学习模型的ChatGPT诞生,再次引起了广泛关注,ChatGPT验证了大模型的巨大商业价值和科研价值。ChatGPT不仅是一个对话机器人,它还在机器翻译、问答系统、创意写作、搜索和阅读理解等方面取得了许多成功案例。
为了提高模型的推理能力,OpenAI在2021年利用179G的代码数据对GPT3进行训练,希望通过这种训练提升模型的逻辑推理能力。
既然模型已经开始用代码进行训练,那么人们就开始思考 ChatGPT 这样的预训练模型是否可以更好地用于软件开发?
我们很早就开始了在这方面的思考,针对代码的局部领域关系、线性依赖关系、语法依赖关系、控制依赖关系、多层次结构交互关系等进行了研究,提出了多种学习模型。
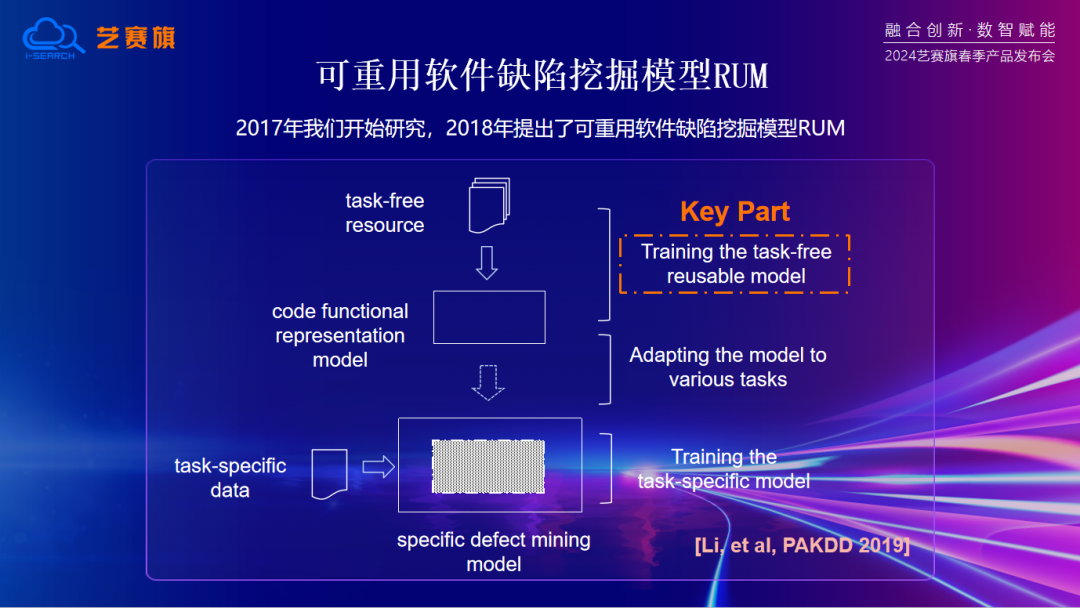
研究过程中遇到了数据量不足的问题,难以支撑训练出一个比较好的深度模型。因此,我们开始在网上获得大量代码信息,做出一个通用的代码表征模型,并通过代码复用技术,将其应用到各个任务中,从而获得更好的性能。
因此我们提出了一个基于模型复用的框架,基于此框架训练出一个可重用的软件缺陷挖掘模型RUM,并将其应用于不同的缺陷挖掘任务中。这是最早的使用预训练模型来解决不同任务的思考模式,也为后续的研究方向奠定了基础。
ChatGPT就是这样一个经过语言和代码训练的通用模型,在软件开发过程中的具有很大的应用潜力。工业界对此也有深入的跟进和思考,如Microsoft和OpenAI联合开发的GPT代码生成模型CoPilot,以及GitHub和OpenAI合作开发的代码生成模型Codex,都在代码生成领域取得了显著的成功。
在使用ChatGPT的过程中,它展现出了强大的语言和逻辑推理能力,能够辅助开发者编写高质量的代码。例如,当需要编写一个Python版本的快速排序代码时,ChatGPT可以直接生成代码,并附带对该代码的解释。
然而,当涉及到业务代码时,ChatGPT的性能就会受到挑战。在自动化流程挖掘中,生成相应的流程挖掘代码是一项关键任务,这需要解决ChatGPT在业务代码编写方面的短板。
第一个挑战是 ChatGPT 对语言的过度依赖。作为一个基于语言的模型,ChatGPT在分析代码(即编程语言)时会遇到困难,因为编程语言和自然语言存在显著差异。尽管编程语言可以通过程序员的要求提高代码的可读性,但这并非强制性的。换言之,即使代码的可读性较差,它仍然可以正常运行。因此,如果用ChatGPT这样的模型去分析这样的代码,可能会导致错误。
为此,我们提出了一个相应的尝试性解决方案—— VECOS。这个模型可以对质量非常低的,甚至是反编译出来的代码进行语义分析和理解。
另一个挑战是虽然 ChatGPT 对语言文字很敏感,但对编程语言的功能语义建模能力有限。
对此,黎教授举例说明,有两段 Java 代码,可能在词汇表级别完全一致,但实际功能和语义却有显著差异。这是因为在程序设计中,程序结构中的内在关系尤为重要。如果要生成或理解代码的功能,就需要对这部分进行有效建模。然而,目前的ChatGPT模型只抓住了文字层面的关系,却忽略了程序内蕴的结构联系。因此,需要对相应的程序结构语义进行特殊的建模。
针对这一问题,我们开始探讨如何在以Transformer为基础模型的预训练大模型上考虑代码结构特征?
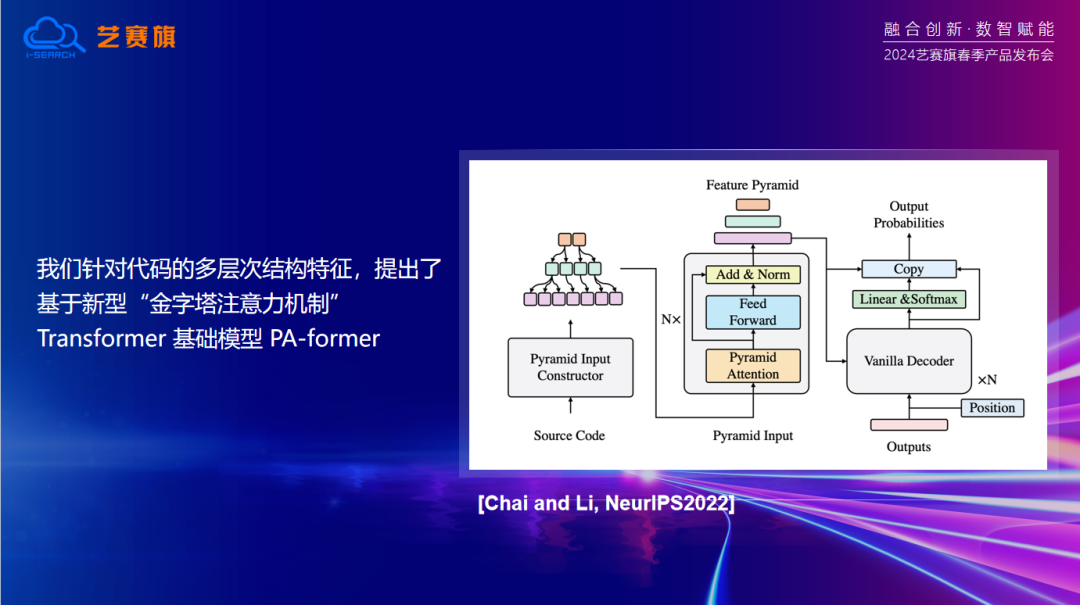
Transformer是目前最先进的神经网络结构之一。它通过自注意力机制,能够捕捉到输入序列中的长距离依赖关系,从而实现对复杂语义的理解。这种强大的能力使得ChatGPT能够处理各种复杂的自然语言任务,包括问答、文本生成、摘要等。并且针对代码的多层次结构特征,我们提出了基于新型“金字塔注意力机制” Transformer 基础模型 PA-former。
以上所述的基础理论方法和技术已被应用到实际业务场景中,包括艺赛旗的流程挖掘技术及业务场景,以帮助其更好的进行业务流程的发掘。
南京大学与艺赛旗共同发起的智能研究院在人工智能及超自动化领域的研究成果,充分展现了其卓越的创新能力。这些研究成果不仅在学术界受到高度认可,也在实际应用中取得了显著的成果。随着科技的不断进步和发展,相信这些成果将在更多领域发挥重要的作用。
 企业平台
企业平台 发现评估
发现评估 自动化
自动化 行业解决方案
行业解决方案 业务解决方案
业务解决方案 合作伙伴
合作伙伴 生态联盟
生态联盟 咨询服务
咨询服务 培训服务
培训服务 交流社区
交流社区 客户成功
客户成功 产品文档
产品文档
 公司介绍
公司介绍 新闻列表
新闻列表 联系我们
联系我们 加入我们
加入我们